ParSiTi is a research project funded by ANR (ANR-16-CE33-0021). It is a 4 year project spanning from Nov. 2016 to Nov. 2020.
Social media and other forms of online communication have triggered the emergence of new forms of written texts and increased the volume of multilingual user-generated content (UGC). Making these unlimited streams of non-canonical texts automatically understandable and actionable opens new scientific and social challenges. This is the main focus of the ParSiTi project.
 Context
One of the most striking influences of social media on society is how
they evolved to impact our perception of events. For instance, during
the various Spring Revolutions, Facebook users were in the front line
of the information war; more recently, during the November 2015 Paris
Attacks, Twitter was used to gather information about the victims and
to offer shelter to those stranded by these attacks. These events
generated a steady flow of global textual interactions, crucially
highlighting the lack of accurate tools to automatically process and
understand these information streams.
Context
One of the most striking influences of social media on society is how
they evolved to impact our perception of events. For instance, during
the various Spring Revolutions, Facebook users were in the front line
of the information war; more recently, during the November 2015 Paris
Attacks, Twitter was used to gather information about the victims and
to offer shelter to those stranded by these attacks. These events
generated a steady flow of global textual interactions, crucially
highlighting the lack of accurate tools to automatically process and
understand these information streams.
Scientific Challenges UGC, covering among others social networks, blogs and forums, differ from newspaper written languages, on which natural language processing tools are most often trained and tested, in three important dimensions:
- user-generated content is extremely diverse, rife with abbreviations, spelling mistakes, typographical and grammatical errors. It often lacks punctuation and mixes languages. In some cases, the spelling is akin to rough phonetisation. Added to a much richer variability, these phenomena hinder the performance of NLP pipelines.
- Overcoming English, the Web has now turned into a truly multilingual space.
- A strong contextualization as these non-canonical productions are tightly linked to contextual sources (videos, images, memes, game sessions, external URLs) and the inner nature of most social media encourages shorter sentences and threaded messages, which in turn favor the use of elliptical constructions. This leads to strong difficulties in rising ambiguities, for example in case of under-specified anaphoras, which complicate NLP tasks such as parsing or Machine Translation.
The ParSiTi project aims at taking advantage of recent advances in statistical NLP and Deep Learning to address these challenges and improve access to multilingual user-generated content.
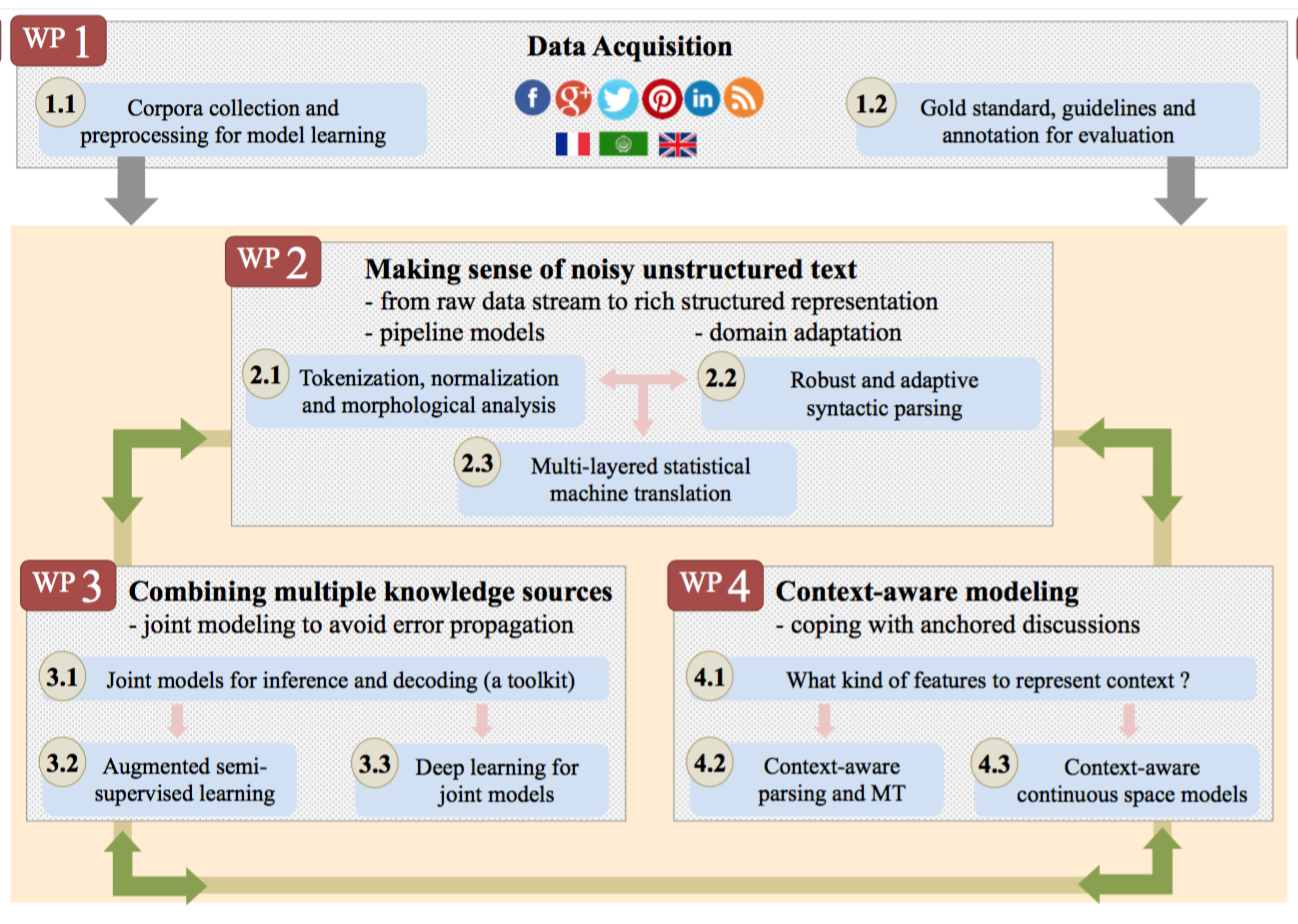 We plan to design and release a fully integrated NLP
software able to automatically process non-canonical texts in their
context. To demonstrate the success of our approach, an accurate
Machine Translation system, able to translate, in context,
user-generated content between French, Arabic and English, will be
developed. Such a system should prove valuable to researchers in
linguistics, social sciences and for innovative private sector
companies. Moreover, our software and data sets will be made freely
available, so that they can be used for further work beyond the scope
of the project, e.g. for information extraction or opinion mining.
We plan to design and release a fully integrated NLP
software able to automatically process non-canonical texts in their
context. To demonstrate the success of our approach, an accurate
Machine Translation system, able to translate, in context,
user-generated content between French, Arabic and English, will be
developed. Such a system should prove valuable to researchers in
linguistics, social sciences and for innovative private sector
companies. Moreover, our software and data sets will be made freely
available, so that they can be used for further work beyond the scope
of the project, e.g. for information extraction or opinion mining.
Developing this software is highly challenging and requires to push existing techniques to their limits, sometimes at the price of questioning assumptions that have long been taken for granted. The ParSiTi project will address three scientific challenges of increasing risk and complexity:
- normalizing UGC and adapting parsing, along with translation models, to their peculiarities
- developing joint models to combine different sources of information without error propagation
- design context-aware models to cope with discussion anchored in a specific linguistic (e.g. comment in a threaded discussion) and extract-linguistic (e.g. images, URL, …) contexts.